Technology Radar Volume 34 まとめ

Technology Radar についてはここにまとめている。
この記事では次のことがわかる。
- 今号のテーマ
- 各カテゴリーごとの Adopt / Caution / ピックアップを紹介
- ピックアップは将来的に影響がありそうなものや面白そうなものを選んでいる
- 個人的な思いなども書いているので参考に
過去まとめ🔗
今号のテーマ🔗
検討メンバーがガラッと変わったのか、毛色の異なる blip が並んだり、過去のものが掘り出されたりしている。まだこなれていないのかテーマのブレや各段階の妥当性について懐疑的なものが多い。
The challenge of evaluating technology in an agentic world: 最近の技術を評価する取り組み🔗
最近は semantic diffusion が激しいというハナシと、コーディングエージェントによる新しいツールの出現頻度が高くなっていることによって、技術をちゃんと評価するのが難しくなっている。
とはいうものの、チーム内で議論するときはちゃんと定義を確認した上でやれば良いし、ライブラリーなど採用するときはきちんと評価すれば良いだけなので個人的にそんなに問題だと思っていない。フロントエンドの流れが早いと言われていた時期よりはゆっくりじゃないかと感じている。
技術の評価で一番大切なのは手を動かした上で検討する、これに尽きるのではないか。
Retaining principles, relinquishing patterns: 原則を維持し、パターンを手放す🔗
コーディングエージェントを用いた開発が主流となってきた、つまり開発の方法がガラッと変わってきたので、今まで良しとされてきたパターンが通用しなくなっている。こういう場合はパターンの根底にある概念や、そもそもの目標を再認識して必要なものを組み立てていきましょう、というテーマ。
古いものではミューテーションテストなど、提案時は端末の速度の問題で使えなかった手法が今になって注目されてきていたりする。 DORA メトリクスやゼロトラストアーキテクチャーなど、抽象的なものをきちんと実践できるかどうかが問われている。
Securing permission-hungry agents: 権限に飢えているエージェントのセキュリティ確保🔗
便利なエージェントとはつまりすべてのデータにアクセスできるものなので原理的にセキュリティを確保できない。
MCP の代わりに CLI や Skills を使うべき、一般に配布されているものはきちんと中身が安全だと精査できているものでなければ危ない、といった形でベストプラクティスも変わってきている。
ここは原理的に安全になることはないので、しばらくは注視しておかなければならないだろう。
Putting coding agents on a leash: コーディングエージェントを制御する🔗
コーディングエージェントをひとつの系として見立て、フィードフォワードとフィードバックという制御工学のメタファーを使って制御していこうぜ、というテーマ。フィードフォワードは Skills など計画の精度を上げるアプローチ、フィードバックは出力されたものをリンターやテストなどツールを用いて評価するアプローチとして紹介されている。
Techniques🔗
Adopt🔗
Context engineering: コンテキストエンジニアリング🔗
前回 Assess だったが大躍進。
次の引用ポストと、その元ポストが発祥。
+1 for "context engineering" over "prompt engineering".
— Andrej Karpathy (@karpathy) 2025年6月25日
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window… https://t.co/Ne65F6vFcf
Coding Agent のコンテキストエンジニアリングについては次が詳しい。

最近はコンテキストを管理するために、ドメイン知識を必要な際に呼び出せるようにパッケージングする、という発想で Agent Skills が出現した。
精度よくコンテキスト圧縮をする技術も研究されているようだ。これは coding agent 向けの話題。
LLM を組み込んだアプリケーションを構築している場合はプロンプトのキャッシュ機能がコスト / レイテンシーともに効くだろうとのこと。精度関係ない話しになっとるやんけ。
さて、コンテキストエンジニアリングは一過性のものではなく、将来的にずっと役立つ概念だ。言ってみればメモリー管理のようなもので、 C 言語でメモリーアロケーションから開放まで面倒をみていた時代から、スマートポインター、ガベージコレクションと徐々に意識しなくて良いものになってきた。が、メモリーに関する知識を知っているかどうかが課題解決につながる場合がまだある。これと同じ感じになっていく可能性が高い。
現在はコンテキストが膨らむことで次の弊害が出る。
- 金銭コストが膨らむ
- 回答が返ってくるまでの時間が長くなる
- 回答精度が落ちる
現在の LLM の仕組み的にこれは避けられない。 self attention の計算が過去トークンすべてとの行列演算なので計算量的に O(n^2) になるからだ。逆に、こういう仕組みなので今の精度が得られている。
これらを解決しようとすると、次の方向になるはず。
- コンテキスト圧縮を LLM 側でよしなにやってくれるようになる
- 現在どういうコンテキストなのか意識する必要がある
- attention の計算方法を変える
- 毎回過去の全トークンを見返すという方法をやめることになるので、重要な情報が回答生成にあたって考慮されなくなる可能性が出る
- 重要な情報を切り捨てられないようにコンテキスト管理する必要が出てくる
どう転んだとしてもコンテキストに関する知識が求められたり、現在どうなっているかを意識する必要がある。
今のところは精度、コスト、 UX に直撃するので地道にやっていくことで将来にも役立つ勘所が得られるだろう。
Curated shared instructions for software teams: プロジェクトでのプロンプト共有🔗
前回 Adopt で登場し、今回も Adopt で再登場。鉄板となっている。
開発者向けプロンプトを共有することで作業精度があがったり労力が減るという旨味がある。紹介されている方法は 3 つ。
- プロジェクトテンプレートにプロンプトを含める
- 動くアプリケーションやそのコードを参照せよというプロンプト集
- Agent Skills や Plugin の配布など
1 / 2 番はチーム規模、 3 番は組織規模で使い分ければよいだろう。
DORA metrics: DORA メトリクス🔗
4 年ぶり 4 回目の Adopt 。
DORA メトリクスはデリバリーに関する指標。
なぜこれが今号で Adopt に載っているかというと、AI によるコード生成で速くなったと感じているエンジニアが多いが、それが本当に価値をもたらしているか?という議論から。ここでは再作業率という新たに追加されたメトリクスが重要だとされている。要は LLM によって生成されたコードは動いているのでデプロイまでは以前より速くなる。が、デプロイした箇所に関して何度もバグ修正しているようだと速くなってはいないことが可視化できる。
Passkeys🔗
2 年前 Trial だったのが今回ついに Adopt 入り。
Passkey について特に説明することもないだろう。
日本ではタイムリーに Passkey が認証の第一選択肢になってきている。

Passkey 登録したデバイスを紛失や破損したときにどうアカウントを復旧するか、というあたりが今後の課題になる。ユーザー側では複数デバイスに Passkey 登録しておく、プラットフォーム側では本人確認を徹底するなど。
Structured output from LLMs: LLM からの構造化出力🔗
前回 Trial からの Adopt へ。
JSON など machine readable な形式で LLM から回答を返してもらう。回答内容に対して何かしら処理したい場合にとても便利。
Zero trust architecture: ゼロトラストアーキテクチャ🔗
5 年ぶり 2 回目の Adopt 。
既存システムにエージェントを組み込む際に、どういう経路でアクセスされるかわからないのでクレデンシャルの管理方法を見直して secret manager や OIDC をちゃんと使おうぜということ。たぶん今から新規で組むなら自然とこうなる。
Caution🔗
Agent instruction bloat: エージェントへの指示の肥大化🔗
初登場で Caution 。
AGENTS.md や CLAUDE.md など、エージェント指示は肥大化しがちだ。作業の中でちょいちょい追加しているといつの間にかすごい量になる。
で、これがタスク達成精度を引き下げてしまう。そもそもエージェントの行動原理として指示に従うことが組み込まれているので、タスク達成に必要ない指示でもしたがって行動してしまう。これは単純に行動が増えることによって回答時間が長くなることもだが、コンテキストにノイズが入るのでコンテキストエンジニアリングに逆行するというハナシ。
この点について、指示を生成させるより手書きしたほうが精度向上に寄与する、という研究結果が出ている。
直感的にも妥当で、 LLM は人間好みの冗長な文章を生成するので指示の情報密度が薄い。生成させたものに手を入れるだけでもいくらかマシになるだろう。
また、コードやドキュメントに書いていないことだけ書くべきで、これは単純に更新する箇所が多いと矛盾が生じやすいから。 LLM は十分賢いので聞いてくれたりよしなに扱ってくれたりするが、それも精度悪化の原因になる。
また、これは個人的な感覚だが、行動の指示ではなく生成されるコードや文章のテイストの指示にとどめたほうが精度高いと感じている。コメントは日本語常体でコードから読み取れない意図のみ書く、文章は簡潔に情報密度高く、など。逆にテストコマンドはこれ、ディレクトリー構成はこう、など行動や冗長な情報が入っていると意図した挙動になりづらい。
LLM は現在、十分に賢くなったので行動はプランも含めて考えさせたほうが結果につながりやすい、というだけのハナシかなと解釈している。人間でもコード書いたりテスト実行したりはそれぞれのやり方があるので、それに任せてしまおうという考え方だ。 npm scripts などの作業手順の標準化はアンカーとして大切だが、それで戦場の霧を払えるわけはないので各員の創発性に期待するのが良い、というドクトリン。
たぶん、上の方から有用、な気がする。
- テイスト指示のみ手書き
- 好き勝手手書き
- LLM 生成を整理
- LLM 生成
AI-accelerated shadow IT: AI が加速するシャドー IT🔗
去年から引き続き 3 回連続 Caution 。
Claude Cowork などベンダーも積極的に非エンジニアリング職に対してコードを組むプロダクトを提供しはじめ、ガバナンスの効いてないコードの作成に拍車がかかっている。 OIDC 考慮したコードまで組めてしまうのでいつの間にか正規ルートで情報が漏れてました、ということもあって恐怖。
blip ではサンドボックス内での実験と、作成済みのもののカタログを作ることで対抗しよう、と言っているが、どこまで実効性があるのかは疑問。だってプロンプト打つだけでできちゃうんだもの。カタログの存在を周知したところで登録圧力は高まらないだろう。ゼロトラストネットワークを組織に持ち込んで最低限の制限をかけるなどだが、これだけでかなりの投資が必要になる。
Codebase cognitive debt: コードベースの認知的負債🔗
初登場。
技術的負債よりももう少し複雑な、認知的負債による弊害が意識されてきているよ、という blip 。
ただ、これももう古くて、今年 3 月には intent debt: 意図負債がそれらの源泉だという因果関係が示された。
要は LLM との意思疎通ができていない。プロジェクトにおいて考慮されるべきことを明文化できないのか、コンテキストから抜け落ちてしまっているのか、様々な理由でメンバーである LLM に伝わっていない。そうなると LLM はタスク達成のために学習済みの一般的な判断を適用して、プロジェクトにそぐわないものをこさえてくる。人間が認識している範囲では意図通りに動くもんだから、そのまま認識外の挙動や設計も一緒にコードベースへ埋め込まれてしまう、という塩梅だ。
これに対抗するためには、プロジェクトの目的や制約を明文化しメンテナンスし続けることが必須だ。より PdM 的なスキルが求められてきていると言える。もしかしたら組織やチーム構成、コスト、スケジュールもつぶさに教えてやると精度が上がる可能性もある。
ただ、この明文化とメンテナンスは習得に苦労するスキルでもある。コードのように明確な間違いがわかりづらく、コンパイラーのように何が間違ってるかをわかりやすく指摘してくれるツールも少ないからだ。 LLM に採点を任せたって、人間が気づいていない意図の不足を指摘させるのは原理的に不可能。ブログを書いたり、ピアレビューしてもらったりなどが地道ながら最も効く。意図が足りてないかどうかに気づくか、 intent smell とでも言うものを嗅ぎ分けられるかについては目的との整合性と俯瞰的な構造などを頭に描けなければわからない気もする。リベラルアーツに代表される、社会人的なスキルは土台となるので頑張りましょう、という具合だ。
要件定義、基礎設計、 ADR を中心として、それらの前段となる調査や研究なども記録しておくと、参照可能な意図として機能するだろう。これをウォーターフォール vs アジャイルの文脈で解釈する方もいるが、 LLM を使って開発していると ADR は毎日複数に手が入るし、要件定義や基礎設計も数日でブラッシュアップされていく。これは明確にアジャイル的な動きだ。
仕様駆動開発は広義に捉えたうえでの一流派であれば通用する可能性がある。次で言うところの Spec-anchored かつ、 requirement SPECification 、つまり要件定義まで含む場合だ。

ただ、人によって定義が異なるものを引き合いに出す必要があるのかどうか、指摘されたら上の記事を挙げながら説明する、くらいでいいだろう。
Coding agent swarms: コーディングエージェントの大群🔗
初登場。
swarm は大群、まさに数十以上のエージェントをチームとして用いて開発することを指している。成功例として報告されている C 言語コンパイラーの実装などは仕様がわかりきっているから成り立った、というだけ。要件と仕様がわかりきっていて変動せず、既存のコードが使えない状況においてカネでぶん殴ったら速くできるよ、と。
何を当たり前のことを、という blip なんだが、一点だけ建設的な議論をすると複数エージェントが動く場合にまず対処すべきことは各モデルが持っているバイアス。
この論文は LLM as a Judge というユースケースで発現するバイアスを調べた研究。コードレビューも LLM as a Judge と似た側面を持つタスクと捉えると、ここで紹介されている各バイアスを抑え込めるような構成を組むと迷走を抑えることに寄与する可能性がある。
Coding throughput as a measureof productivity: 生産性指標としてのコーディングスループット🔗
初登場。
LLM が大量のコードを生成するようになったので、コード行数や PR 数で生産性は推し量れないよね、という blip 。それはそう。紹介されている first-pass acceptance rate も測定方法がシェアされてないし、ノールックでマージしてもこの指標は高いままなので使えない。
また、ここで代替として挙げられている DORA メトリクスもソフトウェアの価値を測るものではないということに注意が必要。高速に開発からデリバリーへつなげることが価値提供の前提となる、という理屈で近似指標として使われることが多い。
ちなみに価値を測るための統一的な指標はたぶん定義できない。価値の定量化が難しいこと、売上額や MAU などを価値の近似指標として使っても、デリバリーした機能 / 非機能がどの程度寄与したのかがわからないことが理由として挙げられる。組織内で近似指標として何かを用いる、という決めはできる程度。
生産性を測れるという幻想から早めに気づくのが良い。各種メトリクスは振り返り材料やチーム不全の兆候を見るくらいで使うべき。
Ignoring durability in agent workflows: エージェントワークフローでの永続性の軽視🔗
初登場。
要は LLM API が 500 を返したりタイムアウトする状況でも機能を提供できる作りにせよ、ということ。
MCP by default: 何も考えずに MCP で実装🔗
初登場。
CLI で同様のことはできるので MCP である意味を考えよ、という blip 。 UNIX 哲学に沿った CLI を提供すればコンテキストも圧迫しない。
別プロセスを参照するとか、 LLM に依頼するタスクのほとんどが常に依存するような場合に、 MCP は活きてくる。
Pixel-streamed development environments: 画面転送による開発🔗
初登場。
サーバー上で IDE などを起動したその画面を手元に転送してコーディングするらしい。レイテンシーがあったり細かい文字は潰れて見えなかったりするらしい。何その地獄。
ピックアップ🔗
Feedback sensors for coding agents: コーディングエージェント用のフィードバックセンサー - Trial🔗
初登場。
コーディングエージェント自体に生成コードを評価する方法を教え、それらからのエラーや警告などを自動で直させる。要はツールに任せられるところはすべて任せてしまおう、人間の認知リソースをもっと人間でしかできない判断に使おう、という主張の blip 。
評価する方法はわかりやすいところではフォーマッターやリンターなど。こういった決定論的に動作するツール以外に、次のような自動コードレビューなども応用としてアリだ。

ただし生成したエージェント自体にレビューさせるよりも別系統、ベンダーが異なるエージェントにレビューさせたほうがバイアスを打ち消せる可能性があるので、この記事のまま使うのはやめたほうがいい。
Mutation testing: ミューテーションテスト - Trial🔗
初登場。
1971 年に提案されたもので、かなり初期から発見されていた方法論。当時はコンピューティングリソースの関係で使い物にならなかったようだが、この時代になって有用性が見直された。
テストケースもコーディングエージェントに生成させる時代では、テストケースの有効性を測るために自動化できるツールがほしい。ミューテーションテストはコード側を変異させ、テストが失敗、つまり変異を検出できるかを試すもの。
これはフィードバックにあたるものなので、そもそものテストスイートの設計がおかしければテストケースだけ増えていって CI 実行時間がつらい、となったりする。フィードフォワードとしてユースケースを BDD 的に使える形まで明文化したり、デシジョンテーブルを書いたりするなど、適切な指示を与えてやることが望ましい。
Feedback Flywheel: 継続的なフィードバックが重要 - Assess🔗
初登場。
コーディングエージェントとのやりとりを振り返って、指示として明文化してまた試す、というのが基本プロセスのようだ。アジャイル開発におけるイテレーション最後の振り返りと同様の立ち位置となる。プロンプトごとに振り返りを回すので頻度は多いが。
チームで共有すべき改善はどんどん実施して PR として合意を取っていくスタイルで良いはず。 Skills などは議論しながらどこまでやるかを決めていけばいいだろう。
ただ、タスク分解と順番整理、プランの立て方のような個人ワークに留まる、いわば好みをどうやって育てていくか、という点。 CLAUDE.md や AGENTS.md などはホームディレクトリー以下のものを見てくれるのでそれで管理すれば良いが、 Skills を育てたい場合が難しい。 /.claude/skills/personal/ 以下に置いておいてここだけ .gitignore に指定するなども考えられるが無理やり感は否めない。ベンダーのサポートを待ちたいところ。
Skills as executable onboarding documentation: 使い方紹介としての Skills - Assess🔗
初登場。
実行可能なドキュメントとして Skills を整備しておくとうれしい、という blip 。
- 依存ツールのインストールや初期設定などプロジェクトセットアップ用
- ライブラリーや API を公開している場合はその使い方を Skills として配布する
- デザインシステムなど組織内部のプラットフォームの利用方法を Skills として配布する
2 と 3 はユーザーが組織の外部か内部かの違い。最近は OSS で Skills 配布していたりなどもあるので身近になってきた。
プロジェクトの新規メンバーへのオンボーディング用の Skills については言及がなかった。たぶんコンテキストエンジニアリングの文脈で制約や慣習などは何らかのプロンプトやドキュメントで明文化しよう、という前提に立っているからだ。それらが多くなってきたら、どう使っていくかを紹介する Skills を定義するフェイズになる可能性はある。
Toxic flow analysis for AI: AI が悪さをするフローを分析する - Assess🔗
前号に引き続き Assess のまま 2 回目の登場。
引き続き LLM が悪さできてしまう条件を成立させないように、というもの。そのための概念として lethal trifecta が紹介されている。
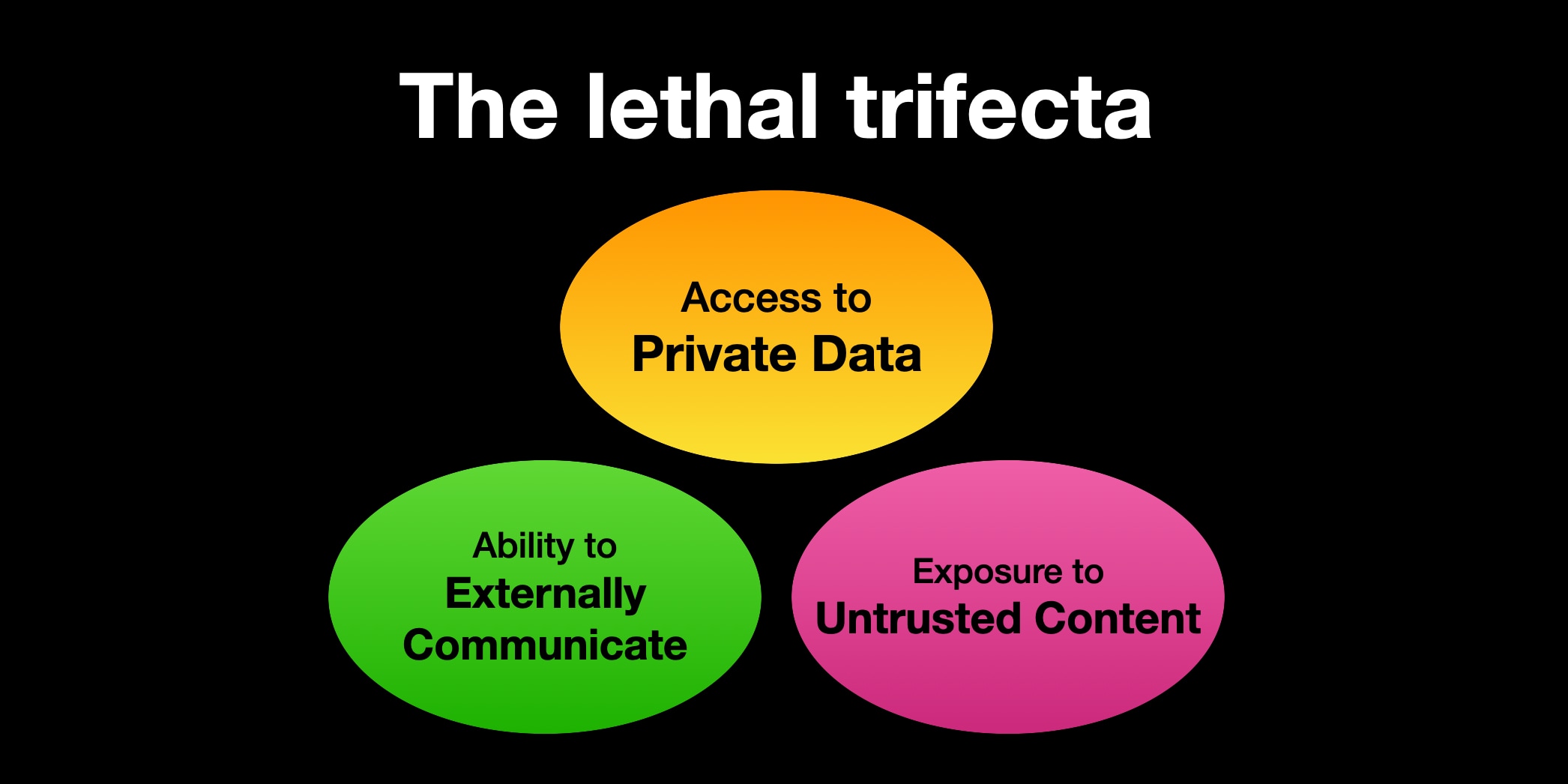
- 安全でない指示の入力
- 機微情報へのアクセス
- 外部への送信能力
要は「安全でない指示」に「機微情報」を「外部へ送信」するよう書かれていたら LLM はそのとおりに動いてしまう、ということだ。
開発時の侵害された依存パッケージ経由の指示やコードや GitHub issue のコメントに書かれた指示によって、攻撃が成立したりする。 Opus 4.7 は指示への追従能力が高くなっているのもあり、 1 を完全に防ぐのは難しい。
仕事や個人的なタスクの効率化、相談などには 2 が必要、というか LLM を使う目的はそれらが多いので機微情報へのアクセスは常に許可される状態にある。が、少なくとも外部に送信されてしまうと金銭的なコストが発生するようなものは極力 LLM が触れられる位置に置くべきでない。
Platforms🔗
Adopt🔗
なし。
Caution🔗
なし。
ピックアップ🔗
なし。
Tools🔗
Adopt🔗
Axe-core🔗
初出は 2021 年、今回 Adopt 入り。
アクセシビリティ診断ツール。フロントエンド開発の文脈では「いつもの」というくらい浸透している。消費者向けサービスであればリリース前に通すのが良いだろう。
Claude Code🔗
前号で Trial からの今号で Adopt 。
精度が良くどんなエディターとも組み合わせられるので、まずここからはじめてみるというのも良いだろう。モデルとの相性はあるので気になったら他ベンダーが提供するものを試すという形で。
すでにかなり多機能なのでイチから使いこなすにはあるていど向き合う必要があるが、公式の記事も揃ってきたのでそれほど苦労はしないはず。多少の詰まりはそれこそ Claude Code 自体に聞いてしまえば解決する。
Cursor🔗
一昨年 Assess で登場、今号で Adopt へ。
コーディングエージェントという市場を切り開いたもの。様々なベンダーから後続も次々投入されている。
VSCode からフォークしたエディターで、各 LLM モデルを使い分けられること、文脈を理解した複数行の自動補完を効かせられることなどが利点だ。
Kafbat UI🔗
初登場 Adopt 。
Apache Kafka の Web UI 。 Kafka を使っているなら一緒に使うのが鉄板、ということらしい。
当の Kafka はイベントストリーミングベースのプラットフォーム。リアルタイムで様々なイベントが発生し、それらを着実に処理しなければならない場合は役立つだろう。
mise🔗
2 年前に Assess で初登場、今回 Adopt 入り。
言語やツールなど開発環境のセットアップをこれひとつで、というもの。環境変数の管理やタスク定義と実行もできるので、これひとつ入れておけば大抵の場合問題ない。
ちなみに「ミーズ」と読む。フランス語らしい。
Caution🔗
OpenClaw🔗
初登場 Caution 。
使いこなせれば便利なパーソナルアシスタント、だが lethal trifecta がすべて揃うので、抜かれる覚悟を持つくらいでなければ使えない。少なくとも仕事用の端末で動かすのはやめたほうが良いだろう。
ピックアップ🔗
agent-scan - Assess🔗
Assess で初登場。
Snyk 社が提供しているエージェント向けセキュリティスキャナー。 MCP や Skills などを見て危ないところを教えてくれる。
ただ、 Skills の内容や LLM が呼び出すツールの名前や説明などが Snyk 社に送信されるのでその点のみは注意が必要。
CodeScene - Assess🔗
Assess 初登場。

開発プロセスのメタデータを分析するためのツール。コードの複雑度と git の変更履歴をもとに、 LLM が編集をミスりやすいコードを特定したり、特定の開発者しか触らないコードを可視化したりと、技術的負債を把握するために役立つ。
Languages & Frameworks🔗
Adopt🔗
Apache Iceberg🔗
2022 年初出、今号で Adopt 入り。
S3 互換のオブジェクトストレージ上にレイクハウスを構築するためのもの。
Declarative Automation Bundles🔗
2024 年初出から 2 年経って Adopt 入り。
Databricks の IaC ツール。 Databricks 使ってるなら一緒にどうぞ、というもの。
React JS🔗
2015 年初出、 2016 年に Adopt 入りしていたが、 10 年経って再度の Adopt 。
再登場の理由は React compiler や React Foundation への移管ということらしい。が、実態として Vercel の意向がかなり入ってきており、代替として Remix などが盛り上がっているのでズレている感がある。
React Native🔗
2015 年に登場、 2016 年に Trial だったが今回初の Adopt 入り。
新アーキテクチャーによる高速化が決め手らしいが、旧アーキテクチャーでも一般的なアプリであればサクサクだったので ThoughtWorks で処理させてるデータが大規模すぎる疑惑。これもちょっとズレてる blip 。
Svelte🔗
2020 年登場、今回 Adopt 。
軽く速い。 SvelteKit による開発のしやすさも手伝って React 以外の選択肢として固い。
Typer🔗
初登場 Adopt 。
型アノテーションから CLI ツールを作るライブラリー。フレームワークではない気がするが…?
Caution🔗
なし。
ピックアップ🔗
LiteLLM - Trial🔗
2024 年初出だが最近は Trial 止まり。
様々な LLM を OpenAI 互換 API で呼び出せるようにするもの。リトライやロードバランシング、トレース記録やレートリミットなどもかけられるので、一枚かましておくだけで LLM アプリの開発に必要なものが揃う。